深度学习
本文最后更新于 2025年1月18日 凌晨
前言
教材情况:
| 课程名称 | 选用教材 | 版次 | 作者 | 出版社 | ISBN 号 |
|---|---|---|---|---|---|
| 神经网络与深度学习 | 《神经网络与深度学习》 | 1 | 邱锡鹏 | 机械工业出版社 | 978-7-111-64968-7 |
学习资源:
- 教材官网:https://nndl.github.io/
- 配套内容:https://github.com/nndl/
- TensorFlow 文档:https://tensorflow.google.cn/api_docs/python/tf
- Pytorch 文档:https://pytorch.org/docs/2.0/
为什么要学这门课?
还记得 NJU 的 jyy 老师在上 OS 课程时说过的一句话,“我们现在学习的微积分是 300 年前的人类智慧结晶,何不再学学 50 年前的人类智慧结晶?”印象深刻。当一切都可以用层层嵌套的简单函数模拟时,人类社会必将发生翻天覆地的变化!
会收获什么?
如何搭建一个网络?如何优化网络结构?背后的原理是什么?
概述
表示学习是什么?与传统的特征工程目的一致,为了得到数据中的更好的特征。不同的是,特征工程中的特征选择、特征映射等策略都是可控的方式,而表示学习就是利用深度学习从数据中学习高层的有效特征。
深度学习是什么?我们知道机器学习就是在手动处理完特征后,构建对应的模型 预测输出。而深度学习就是将机器学习的手动特征工程也用模型进行 表示学习 来学习出有效特征,然后继续构建模型 预测输出。如下图所示:
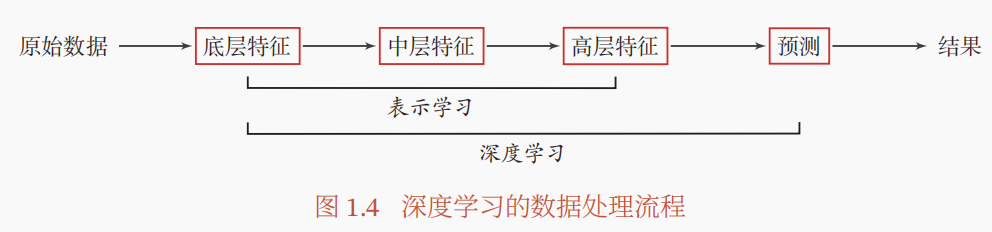
为什么会有深度学习?最简单的一点就是,很多特征我们根本没法定义一种表示规则来表示特征,比如说对于图像,怎么定义复杂的图像的特征呢?比如说对于音频,又怎么定义复杂的音频的特征呢?没办法,我们直接学特征!
神经网络是什么?就是万千模型中的一种,仅此而已。
为什么用神经网络进行深度学习?有了上面对深度学习定义的理解,可以发现其中最具有挑战性的特点就是,模型怎么知道什么才是好特征?什么是不好的特征?神经网络可以很好的解决这个问题。通过由浅到深层层神经元的特征提取,深层的神经元就可以学习更高语义的特征,并且通过这种方式也可以实现「端到端」的学习方式,而不用像机器学习的方法那样,先选特征再学习。并且神经网络模型也可以很好的解决深度学习中特征的「贡献度分配」问题。
在机器学习中,我们学习到了诸如线性模型、决策树模型、贝叶斯模型等模型,下面我们将正式开始深度学习中神经网络模型的学习。
基础网络模型
1 前馈神经网络
前馈神经网络 (Feedforward Neural Network) 就是网络模型中的全连接层。通过向前传递数据,向后更新参数,实现学习和拟合的功能。
前馈神经网络模型的学习准则一般采用交叉熵损失,优化算法一般采用小批量随机梯度下降 (Mini-batch Stochastic Gradient Descent, 简称 Mini-batch SGD) 算法。
1.1 神经元
网络模型中的最小学习单元是什么?神经元。每一个神经元接受输入 ,通过设定好的激活函数 ,给出输出 。神经元中的激活函数大致种类极多,主要有以下 3 种:
- S 型函数。Sigmoid 函数。例如 logistic 函数和 Tanh 函数。
- 斜坡函数。Relu 函数。
- Swish 函数。复合函数。
激活函数的 4 个原则是什么?为什么?。非线性、可导、单调、有界。为了确保网络可以拟合复杂的映射关系,需要激活函数是非线性的;为了便于对网络求导从而进行参数更新,需要确保激活函数是可导的;为了防止对网络求导的过程中出现梯度消失或者梯度爆炸,需要确保激活函数是单调并且有界。
1.2 反向传播算法
注:我们定义输入层为前,输出层为后。
在进行随机梯度下降时。经过简单的推导可以发现,第 层的损失 依赖于后一项的损失 ,于是每一个样本更新参数的逻辑就是从输出层开始逐层往前直到第一层隐藏层进行更新。
2 卷积神经网络
为了解决全连接网络不能学习到局部不变性的缺点,卷积网络应运而生。卷积网络有三大特征:局部连接、权重共享、时/间上的次采样。
2.1 卷积方式
等宽卷积、宽卷积、窄卷积;
转置卷积;
空洞卷积。
2.2 卷积网络
卷积神经网络的典型结构如下图所示:
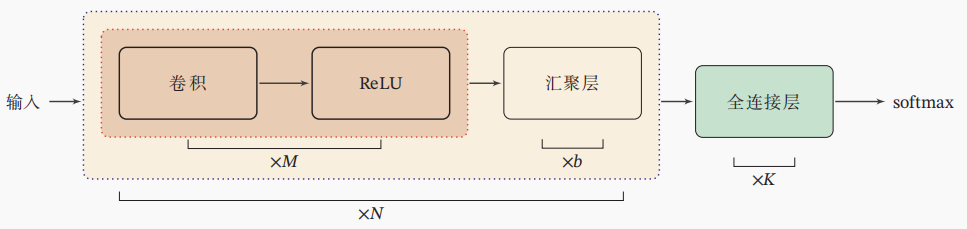
卷积层。对于二维卷积而言,我们假设输入共有 D 个图像,需要学习 P 个特征,并不是只需要学习 P 个卷积核的,对于每一个特征需要单独对每一张图像学习一个卷积核,因此需要学习 个卷积核。
汇聚层/池化层。从上面的卷积层学习逻辑可以看出其实参数量和全连接层相比还是很大,汇聚层就是通过压缩卷积核大小来降低参数量;与此同时,通过汇聚也可以起到去噪作用。
其他卷积网络:
- AlexNet [2012]。使用了 ReLU 激活函数,使用 GPU 并行计算,使用了数据增强;
- VGGNet。
- Inception 网络 [v3, 2016]。将多个等宽卷积的结果进行堆叠;
- 残差网络。由于恒等模型 无法学习到,故将线性模型转化为 并来学习新的模型 。可以解决梯度消失的问题;
- GoogleNet。
- DenseNet。
2.3 参数学习
同样是反向传播算法通过梯度下降进行优化。
3 循环神经网络
监督学习任务:
- 序列到类别模式。例如「序列分类」中的情感分类任务:给定一个语言序列,分析序列的类别;
- 同步的序列到序列。例如「序列标注」任务中的中文分词:给定一个中文序列,对序列中每一个词语进行词性分析;
- 异步的序列到序列。例如「序列编码解码」任务中的机器翻译:输入序列和输出序列不需要有长度的严格对应关系。
时序预测任务:时序序列的数据集形如
- 传统机器学习方法:自回归模型。具体的,模型 被称为 P 阶自回归模型。可以看出这种模型仅仅利用到了标签值并且定义当前标签值与曾经的标签值呈线性关系。
- 前沿深度学习方法:RNN 模型、LSTM 模型、时序卷积模型、Transformer
视频讲解一些具体的应用:https://www.youtube.com/watch?v=EEtf4kNsk7Q
4 注意力机制与外部记忆
5 网络优化
为了能够让一个网络模型「训练速度更快」和「泛化性能更好」,我们可以采用各种网络优化策略。针对一个神经网络,可以有如下五个角度的网路优化策略。
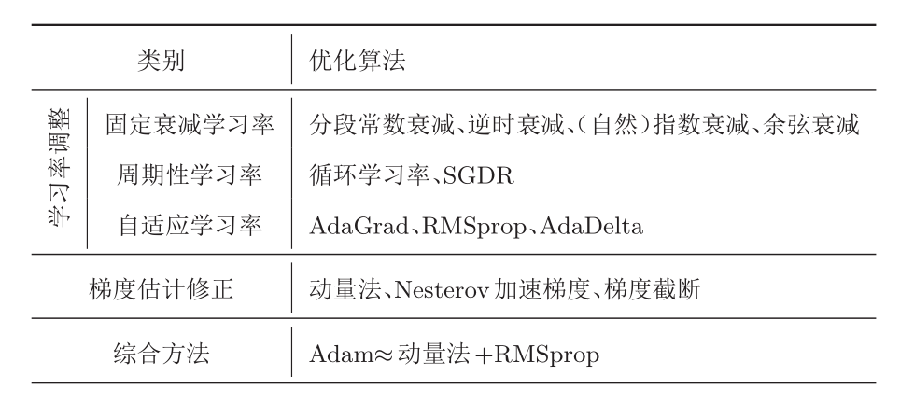
5.1 更好的优化算法
5.2 更好的参数初始化方法
基于「范数保持性」的参数初始化方法
5.3 更好的数据预处理方法
逐层归一化。
5.4 更好的网络结构
ReLU 激活函数、残差连接。
5.5 更好的超参数优化方法
超参数:
- 层数
- 每层神经元个数
- 激活函数
- 学习率(以及动态调整算法)
- 正则化系数
- mini-batch 大小
超参数优化方法:
- 网格搜索
- 随机搜索
- 贝叶斯优化
- 动态资源分配
- 神经架构搜索
mini-batch 与学习率的关系。对于网络中的超参数,如何进行选择呢?最朴素的方法就是网格搜索。对于随机梯度下降的参数优化算法,批大小与学习率一般成正比,即一批训练数据量越多,学习率越高。这是因为一批的训练数据越多,泛化能力就越高,对应的学习率就没必要太低。
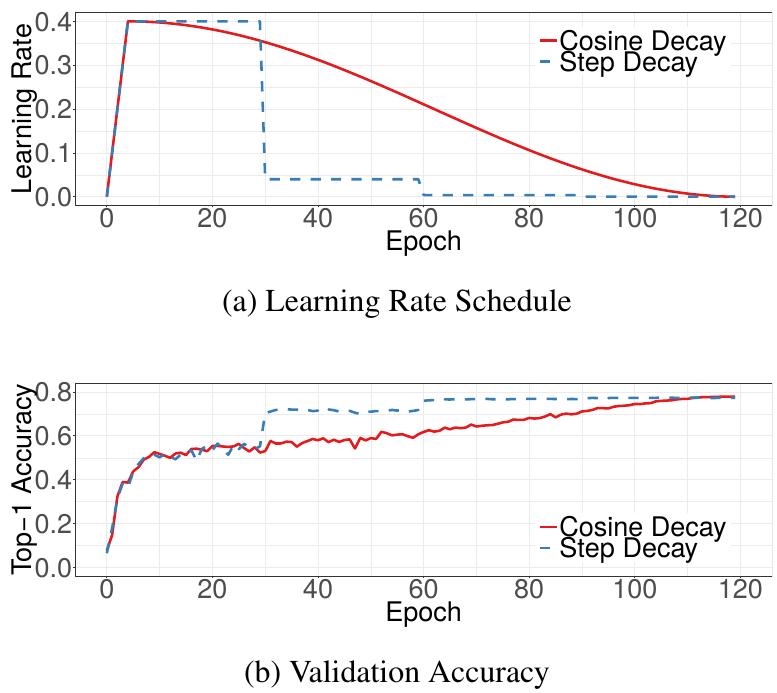
学习率的动态调整算法。一般来说就是两个阶段,在初期的阶段,学习率线性增长,在之后的阶段中,学习率逐渐衰减。详情见 Facebook 的这篇论文 Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour [2018]。
下图展示了预热学习率调整的学习效果。图源:Bag of Tricks for Image Classification with Convolutional Neural Networks [2018]。
进阶模型
6 序列生成模型
7 深度生成模型
本章我们学习深度生成模型。用一句话概括就是使用深度神经网络训练一个模型使得其输出结果符合某个预定的分布。
-
变分自编码器 VAE
-
生成对抗网络 GAN
-
Stable Diffusion:经典的文生图模型。分为以下三个部分,这三个部分均可以单独训练:
-
编码器
-
生成模型
-
解码器
-