python-basic
本文最后更新于 2024年9月1日 下午
Python 基础
本文记录 Python3 语法相关的内容。
浅析 py 中的数据类型
前言
在写 py 的函数时,想要实现下述 C++ 的语法:
1 | |
但是忽然想起来 python 传参时虽然都是引用但是门道有所不同。概念模糊已久,故写此博客权当强化记忆。
数据类型
在 python 中,可以按照 数据的可变性 将所有的数据类型分为两大类:
- 不可变数据类型 :整数
int、浮点数float、字符串str、元组tuple - 可变数据类型 :列表
list、字典dict、集合set
python 中的很多语法知识都是围绕这两种数据类型分别展开,接下来将从 万恶的万物引用、浅拷贝与深拷贝、函数参数传递 三个视角来理解与运用这两种数据类型。
理解与运用
一、万恶的万物引用
在 python 中「所有的一切都是引用」这句话已经听烂了,但是从未实践证实一番。所谓的万物引用可以从 C++ 的赋值和 Python 的赋值进行对比。
在 C++ 中,数据的赋值语句就相当于拷贝构造,即相当于重新开辟一块内存空间用于被赋值的新变量。比如下面的程序:
1 | |
我们知道程序运行时,对于一个数据的存储相当于在内存中开一块临时空间,直到一个逻辑段结束将会自动销毁变量并释放内存空间。在上述 C++ 程序段中,赋值就相当于重新开辟一块内存空间用于存储拷贝的新变量。但是在 Python 中截然不同:所有的赋值全都是一个引用,也就是说所有赋值后的变量都和原始变量一起指向同一块内存空间。比如下面的程序:
1 | |
那岂不是牵一发而动全身?我改了其中一个,其余的引用岂不是都被改动了?的确是如此。
1 | |
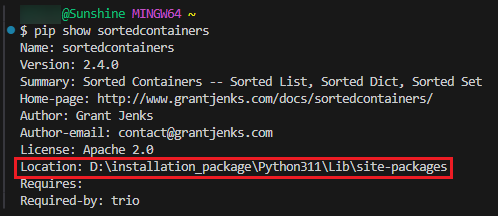
上述所有的示例都可以用下面一张图来表示:C++ 中的变量相当于盒子,简单的赋值语句就相当于重新拿一个盒子装原来的数据;而 Python 中的变量相当于标签,简单的赋值语句就相当于所有标签都贴到了同一块数据上:
当然了,不可变数据是无法进行上述的「单点修改」的,只有重新构造一个对象,比如重新赋值、拼接、截取等操作。但此时无论是可变数据类型还是不可变数据类型,重新构造一个对象并进行赋值其实就相当于「重新开辟一块内存并贴上标签」了,和引用的关系不大,如下面的程序段:
1 | |
此时就相当于这样的图例:

有了上述的知识储备后,理解接下来的知识简直就是易如反掌。
二、浅拷贝与深拷贝
一句话概括:浅拷贝只会拷贝原始对象的第一层数据,其中的不可变数据就会拷贝出一个全新的对象,而其中的可变数据仍然是引用;深拷贝会递归的拷贝原始对象的每一层数据从而构造出一个全新的对象。
1 | |
三、函数参数传递
在前文知识的铺垫下,理解函数参数的传递简直就是喝水,下面开始讲解。既然全都是引用,那么在函数传递参数时也是如此,所有的形参都是实参的引用,于是就回到了「一、万恶的万物引用」中介绍的:
-
若实参是可变数据类型,相当于 C++ 中的引用传参。那么对形参的「单点修改」操作也会改变实参的数据。当然如果对形参赋值全新的对象则并不会改变实参的值,因为让形参指向了新的栈空间。
-
若实参是不可变数据类型,相当于 C++ 中
const级别的引用传递。那么就无法对形参进行「单点修改」操作。只能构造一个全新的对象重新赋值给形参,同样的,此时的形参就不再是实参的引用,而是指向了全新的栈空间。
实例程序如下:
1 | |
可以看到:无论是可变数据类型还是不可变数据,函数调用完成之后地址都不会发生改变。
- 对于可变数据类型:在函数中可以进行重新赋值,也可以进行单点修改。如果重新赋值,形参的地址值会发生改变,实参保持不变;如果单点修改,形参的地址值保持不变,实参发生改变。
- 对于不可变数据类型:在函数中只能进行重新赋值。形参的地址值会发生改变,实参保持不变。
此时再回到一开头提到的,可以通过传递整数实现吗?答案是不可以。因为 int 在 Python 中是不可变的,无法在函数中进行「单点修改」操作,我们只能将其装入可变数据类型比如 list 中实现在函数中通过修改形参达到修改实参的目的。
题外话
不可变数据并非真正的不可变。如果不可变数据其中嵌套了可变数据,仍然可以修改其中嵌套的可变数据;当然不可变数据仍然不可修改。比如下面的程序:
1 | |
参考
查看库的安装位置
由于本地安装了多个 python 解释器,所以想要打印某个版本的解释器下载的「包或模块」的路径,整理一下大约有两种方法
方法1:使用模块内置方法
如果模块内置了 __file__ 方法,则可以直接打印出来:
1 | |
方法二:基于 pip 方法
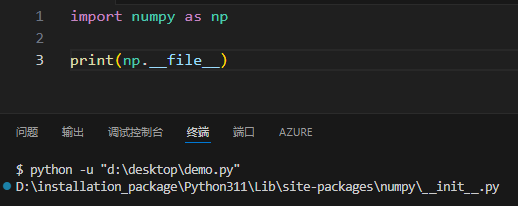
有些库没有内置上述 __file__ 方法,可以使用 pip 指令进行打印:
1 | |
例如想要打印 sortedcontainers 包的安装路径:
1 | |